eXtensible Markup Language
XML est un langage de marquage constitué de balises tout comme HTML. Il se situe à mi-chemin entre SGML - le langage de référence en milieu professionnel pour la gestion électronique des documents (GED) - et HTML que l'on rencontre tous les jours sur l'internet.
Tout comme son cousin HTML, XML est directement issu de SGML. Cependant, il s'en rapproche davantage dans le sens où l'ont peut dire que XML est une forme simplifiée de SGML, car ce dernier est trop complexe pour s'afficher sur le WEB.
XML est l'acronyme de eXtensible Markup Language,
cela signifie que XML n'est pas un langage sémantiquement figé comme peut l'être
HTML mais au contraire un langage ouvert. C'est à dire que l'auteur d'un document
XML peut créer ses propres balises, par exemple : la balise <INSTRUMENT>
peut être définie pour désigner un instrument de musique. Cela s'écrirait de
la façon suivante :
<INSTRUMENT>Guitare</INSTRUMENT> |
Dans un document XML, on s'efforcera de ne pas tenir compte de la mise en forme mais seulement du contenu de celui-ci; la mise en forme étant réalisée par la feuille de style.
Dès lors, ont peut imaginer d'innombrables possibilités que nous offre un tel
langage; par exemple dans l'échange de données informatisées (EDI). Prenons
par exemple le secteur automobile, on pourrait employer les balises suivantes
pour décrire un véhicule: <TYPE MINE>, <CHASSIS>,
<MOTEUR>, <COULEUR>, ...
Les données pouvant être structurées, comme on définirait un enregistrement Moteur dans tout langage de programmation ou bien dans une base de données, en XML on écrirait :
<MOTEUR> |
Et puisque dans un document XML l'information pertinente est marquée par des
balises portant des noms significatifs, il sera plus facile de retrouver l'information
en s'appuyant sur le nom de ces balises pour effectuer des recherches.
En effet, en HTML on ne sait faire actuellement que de la recherche
plein-texte (full-text), ce qui la plupart du temps nous retrouve beaucoup
de documents qui n'ont rien à voir avec notre recherche de départ, c'est ce
que l'on appelle le bruit.
Dans notre exemple :
- Un moteur de recherche pourrait aisément retrouver tous les documents traitant des moteurs 16 soupapes équipant un chassis d'un type donné. On serait alors sûrs que les réponses correspondraient exactement à nos critères de sélection. Ainsi, les autres documents ne traitant qu'un seul de ces deux critères ne seraient pas retournés.
- De même que l'utilisateur obtenant ces réponses pourrait demander à son application de les classer par puissance de ces moteurs.
XML a été développé par le XML Working Group (originellement connu comme le SGML Editorial Review Board) formé sous les auspices du World Wide Web Consortium (W3C) en 1996. Il était présidé par Jon Bosak de Sun Microsystems avec la participation active du XML Special Interest Group (anciennement SGML Working Group) également organisé par le W3C.
Les objectifs de conception de XML sont les suivants :
Remarque : Ceci est un extrait des spécifications officielles,
bien entendu cela reste très théorique car aujourd'hui nous en sommes encore
très loin. Vous vous apercevrez par vous-même que l'apprentissage d'XML est
un travail de longue haleine et que les outils de création sont encore rares.
D'ailleurs, tous les exemples de code XML que vous pourrez trouver sur ce site
ont été réalisés avec le bon vieux Notepad !
Cela dit, je ne cherche pas à vous décourager car comme vous le savez, pour
maîtriser tout outil aussi puissant qu'il soit, il faut un certain temps...
SGML (Standard Generalized Markup Language) (ISO 8879) est une norme internationale adoptée dès 1986 pour apporter une réponse à des problèmes que l'expérience vous a appris à bien connaître :
- données consultées par une population d'utilisateurs hétérogènes
- données complexes, comportant des liens dynamiques
- données susceptibles d'être souvent modifiées
- données nécessaires à l'entreprise et à longue durée de vie
- données de nature à être transposées sous divers formats d'édition
Vous trouverez une FAQ à l'adresse suivante : http://lamp.man.deakin.edu.au/sgml/sgmlfaq.txt
SGML dissocie la structure d'un texte de sa présentation physique. A ce titre, il permet de mieux hiérarchiser et conserver vos données.
SGML repose sur le principe du marquage normalisé des éléments qui définissent
la structure logique d'un texte, c'est à dire tous les éléments extérieurs au
contenu d'un texte qui concourent à sa structure (ex : un titre, une liste...).
Cette norme ISO est ainsi fondée sur la distinction fondamentale entre contenu
et présentation physique.
Imaginons un ouvrage qui porte le titre Le langage XML.
On décrira ce titre avec le symbolisme suivant :
<titre>Le langage XML</titre> |
Comme vous pouvez le constater, tous les attributs typographiques sont écartés
de cette représentation. Le texte est systématiquement marqué par une chaîne
de balises entre crochets qui énoncent seulement que l’élément structurel
<titre> est le titre de l’ouvrage.
En généralisant cet exemple, chaque élément de texte (qu'il s'agisse d'un titre,
d'un paragraphe...) est ainsi délimité par des balises, conférant une structure
propre au document. Ainsi, <titre> sera utilisé pour
annoncer un titre qui sera suivi de </titre> (fin de
titre). Il en va de même pour <sous-titre>, <auteur>
SGML permet de distinguer la structure d'un texte de son contenu. Cette distinction est fondamentale pour comprendre certains des apports majeurs de SGML :
- pérennité des documents : parce qu'il organise l’information selon un système de marques universel, SGML ne craint pas les versions successives des programmes "propriétaires" qui rendent les fichiers si rapidement obsolètes. C'est là un atout particulièrement précieux quand on sait que nombre d'industries sont tenues de conserver leurs données techniques pendant vingt ans et plus.
- hiérarchisation des documents : certains documents techniques interdisent l’emploi de notes dans les tableaux, d’autres l’autorisent, d’autres autorisent des listes dans des parties d’ouvrage mais pas dans des sections, etc. C'est à l'industriel de définir au préalable la structure logique de son modèle de document. Grâce aux balises, il est possible de vérifier que le document est bien conforme aux spécifications.
Bien évidement un langage quel qu'il soit ne peut s'imposer du jour au lendemain,
cependant à terme, XML est appelé à succéder dignement à HTML.
Néanmoins, lorsque l'on se rend compte qu'il aura fallu environ 2 ans pour que
la norme HTML 4.0 soit correctement implémentée dans les navigateurs du marché,
on peut se dire que HTML a encore du temps devant lui. D'autant plus que beaucoup
d'entreprises ou de particuliers utilisent encore des navigateurs comme Microsoft
Internet Explorer ou Netscape Navigator dans leur version 3.0.
Cependant, les plus optimistes d'entre nous diront que XML va révolutionner
l'internet, quant aux plus pessimistes, ils diront que XML est une simple évolution
pour le WEB.
En étant réaliste, on ne peut envisager à l'heure actuelle d'architecturer tout
un système d'information ou bien de construire un site internet entièrement
en XML. D'une part, on ne dispose pas encore de tous les outils nécessaires
à la conception de documents, d'autre part toutes les normes qui s'articulent
autour de XML et notamment les spécifications concernant les feuilles de style
ne sont pas encore achevées par le W3C.
Et pour finir, il n'existe à l'heure actuelle que Microsoft Internet Explorer 5.0 qui soit capable de comprendre le XML. A noter cependant que Mozilla - nom de code du prochain Netscape Navigator 5.0 - en version Bêta actuellement supportera aussi ce merveilleux langage.
Toutefois, on peut vraisemblablement imaginer que d'ici d'une à deux années XML sera réellement utilisé dans de bonnes conditions, ainsi XML pourra pleinement montrer toute sa puissance
Afin de représenter un document en XML, il est nécessaire de posséder :
La DTD est utilisée pour décrire la structure et le type des balises utilisés dans la feuille XML, ce qui bien évidemment donne une structure à notre document. A noter que son emploi est facultatif.
Dès lors, on dira qu'un document XML est "valide" (valid) s'il possède une DTD, et s'il n'en possède pas on utilisera le terme "bien formé" (well formed). Un document dit bien formé doit se conformer aux règles de base de XML. En corollaire, un document valide (accompagné de sa DTD) est obligatoirement bien formé.
Concrètement comme en XML on peut créer toutes sortes de balises, et si l'on veut que tous nos documents exploitent la même structure, il convient de parler le même langage. Ceci est donc le rôle de la DTD, que de définir toutes les balises que l'on pourra utiliser pour créer des documents.
En reprenant l'exemple de l'automobile, si dans notre DTD on a définit l'élément MOTEUR et que dans notre feuille XML on utilise l'élément MOTOR, alors il y aura une erreur de provoquée lors de l'interprétation du document par le navigateur.
Le document bien formé
Un document bien formé doit répondre aux critères suivants:
<p>.......</p><IMG SRC="monimage.gif" alt="Image"/> < et & écrits <
et &<?xml version="1.0" standalone="yes"?>(yes, s'il est seul et no s'il est accompagné
d'une DTD)Cette liste n'est bien sûr pas exhaustive, le mieux étant consulter les spécifications à l'adresse : http://www.w3.org/xml
En résumé, pour produire un document XML, il faut :
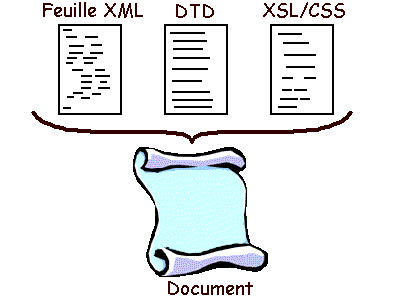
Par abus de langage (à mon sens) on emploie le terme de document XML pour désigner ce que j'ai volontairement appelé la feuille XML. Je pense qu'il aurait mieux valu nommer document XML, le document accompagné de sa feuille de style; mais cela n'engage que moi.
Exemple de code XML
La structure de base est très similaire à celle de HTML. Les feuilles XML peuvent être très simple et vous pouvez créer vos propres balises ou bien utiliser celles prédéfinies dans une DTD.
Notre exemple ne possède pas de DTD :
<?xml version="1.0" standalone="yes"?> |
Une feuille XML est composée de la façon suivante :
Le prologue
La première chose à indiquer est le type de document que l'on crée ainsi qu'il
faut spécifier s'il existe une DTD associée à ce document.
Cela s'écrit sous la forme :
<?xml version='1.0' encoding='UTF-8' standalone='yes'?> |
Nous venons de déclarer un document du type XML dans sa version actuelle 1.0 qui utilise un encodage de type UTF-8 (que nous verrons un peu plus loin) et qui ne possède pas de DTD.
Remarque : il faut bien faire attention à la casse, cette déclaration doit être écrite en minuscule sinon cela provoquera une erreur lors de l'interprétation du document.
Si notre document possédait une DTD, on aurait écrit :
<?xml version='1.0' encoding='UTF-8' standalone='no'?> |
Remarque: On rencontre aussi
<?xml version='1.0'?> |
les autres attributs prennent alors les valeurs par défaut. A savoir encoding = 'UTF-8' et standalone='yes' .
Les différents types de codage
XML utilise les jeux de caractères de la norme ISO 10646 ou Unicode, pour plus d'informations vous trouverez la référence Unicode à l'adresse suivante : http://www.unicode.org
Les plus fréquemment utilisés sont :
- UTF-16 : codage des caractères sur 16 bits
- UTF-8 : codage des caractères sur 8 bits
- ISO-8859-1
Structure d'un document
C'est à l'intérieur la feuille XML que sera stocké tout le contenu textuel d'un document ainsi que des liens vers des images s'il en possède, par le terme document j'entend par là une documentation technique par exemple.
Tout document possède un contenu hiérarchisé (1er chapitre, 1ère partie, ...) et peut donc être représenté sous forme d'arbre.
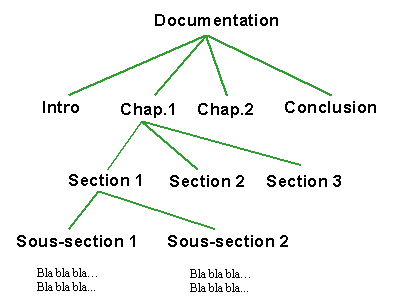
Ceci est donc la structure typique d'une feuille XML à laquelle on exclut toutes les balises de mise en page que l'on trouve en HTML. La présentation physique du document sera réalisée par la feuille de style.
DTD est l'acronyme de Document Type Definition ou en français Définition de type de document. Son rôle va être de définir la structure interne de notre document, c'est à dire qu'il va falloir définir les balises que l'on va utiliser.
Il est à noter que l'utilisation d'une DTD est facultative. Dans le jargon XML, un document qui n'en possède pas est dit bien formé si sa structure est conforme à XML. A l'inverse s'il en utilise une le document sera dit valide.
La DTD peut prendre deux formes :
- soit interne, donc incluse dans notre feuille XML
- soit externe c'est à dire qu'elle est dissociée du contenu du document. C'est sa forme la plus courante, ce qui permet de la réutiliser pour créer d'autre document qui devront avoir la même structure.
Ces deux sous-ensembles forment la DTD.
Exemple de document XML avec une déclaration de type de document :
Document avec DTD externe :
<?xml version="1.0"?> |
Document avec DTD interne :
<?xml version="1.0" encoding="UTF-8" ?> |
Si les sous-ensembles externes et internes sont utilisés, le sous-ensemble interne est considéré comme se produisant avant le sous-ensemble externe. Ceci a pour effet que les déclarations d'entités et de liste d'attributs du sous-ensemble interne ont priorité sur celles du sous-ensemble externe.
Une déclaration de balisage est :
- une déclaration de type d'élément
- une déclaration de liste d'attributs
- une déclaration d'entités ou
- une déclaration de notation
Les feuilles de style sont une addition récente aux fonctionnalités supportées par les navigateurs Web. Elles constituent l'apport le plus significatif à la mise en page de document électroniques en-ligne, et devraient provoquer d'importants changements dans la façon dont l'information textuelle est publiée sur le Web.
En outre, les créateurs de pages Web qui supportent les feuilles de style ne sont pas légion à l'heure actuelle. Aussi, le texte qui suit suppose que vous ayez déjà quelques connaissances de la programmation HTML "à la main"...
Les feuilles de style ne sont ni plus ni moins que des modèles, qui contrôlent l'aspect d'un document. Le concept est familier aux utilisateurs de traitements de texte. Ainsi, dans un document on distingue les titres, les sous-titres et les paragraphes de corps de texte. Chacun d'entre eux possède un aspect qui lui est propre et facilite la lecture du document, en mettant en évidence sa structuration.
Un résultat identique peut maintenant être obtenu en HTML, en surchargeant les balises HTML comme <H1>, <P>, etc. avec des instructions de mise en page. En XML, on s'efforcera de redéfinir tous les éléments contenus dans la DTD. De cette manière la feuille de style ainsi créée sera applicable à tous les documents qui utiliseront cette même DTD.
Il est notamment possible de contrôler l'indentation des paragraphes, les espacements avant et après, les couleurs du texte (avant et arrière plans), etc. En outre, les propriétés définies peuvent être appliquées à plusieurs pages, qui bénéficient alors d'une présentation commune.
HTML était avant tout une norme de description de page basée sur SGML. Aussi ne possédait-il au départ qu'un nombre assez réduit d'instructions (ou balises) permettant de structurer les documents. Par exemple, la balise <I> plaçait le texte en italique, la balise <BR> (de l'anglais BReak line) assurait un saut de ligne, etc.
L'explosion du Web a révélé la nécessité de moyens de présentation plus sophistiqués, permettant de mettre à la disposition des utilisateurs des documents de meilleure qualité esthétique. La norme HTML s'est alors progressivement enrichie de nouvelles balises, assurant par exemple des mises en couleur, le changement de police de caractère, etc.
Cependant, cette approche présentait de multiples inconvénients. Tout d'abord, elle mettait en péril le concept même de la NORME HTML, puisque ces balises étaient proposées soit par Netscape, soit par Microsoft, avant même que le W3C ait pu donner son avis sur la question. Ensuite, HTML était initialement composé d'un petit nombre de balises, que cette effervescence menaçait de conduire rapidement à l'explosion. Enfin, le principe des balises n'était pas adapté à la mise en oeuvre de mises en page sophistiquées.
L'apparition des feuilles de styles promet de régler les problèmes évoqués ci-dessus, en facilitant la création et l'harmonisation des pages Web. L'objectif est d'apporter aux designers de pages Web une partie des facilités dont bénéficient depuis longtemps les outils traditionnels de mise en page.
On en distingue 3 types :
- feuilles de style DSSSL associées aux documents SGML
- feuilles de style CSS associées aux documents HTML et XML
- feuilles de style XSL associées aux documents XML
A noter qu'il en existe encore d'autres, cependant nous nous intéresseront seulement aux plus répandues et en l'occurrence celles citées ci-dessus.
La structure des éléments d'un document XML peut, pour des raisons de validation,
être contrainte à l'aide de déclarations de type d'élément et de liste d'attributs.
La déclaration de type d'un élément contraint le contenu de cet élément.
Les déclarations de type d'un élément limitent habituellement les types d'élément
qui peuvent apparaître comme sous-éléments de celui-ci.
On utilise la notation suivante :
<!ELEMENT NomElément TypeElément> |
Voici les différents types d'éléments que l'on peut utiliser :
Exemples de déclarations de type d'élément :
<!ELEMENT br EMPTY> |
Remarque : Aucun type d'élément ne peut être déclaré plus d'une fois.
On utilise des attributs pour associer des couples nom-valeur aux éléments. Les spécifications d'attribut ne peuvent apparaître qu'au sein de balises ouvrantes et de balises d'élément vide. Les déclarations de liste d'attributs peuvent servir à :
Les déclarations de liste d'attributs précisent le nom, le type de données et la valeur par défaut de chaque attribut associé à un type d'élément donné :
<!ATTLIST NomListeAttribut |
Les types d'attribut XML sont de trois genres:
Le type chaîne peut prendre comme valeur toute chaîne littérale; les types atomiques possèdent différentes contraintes lexicales et sémantiques.
Exemples de déclarations de liste d'attributs :
<!ATTLIST défterme |
Un document XML peut être formé d'une ou plusieurs unités de stockage. Ces unités sont appelées entités ; elles ont toutes du contenu et sont toutes identifiées par un nom, à l'exception de l'entité document et du sous-ensemble externe de la DTD. Chaque document XML possède une entité appelée l'entité document qui sert de point de départ pour le processeur XML et qui peut contenir le document au complet.
Une entité peut être analysable ou non. Le contenu d'une entité analysable est appelé texte de remplacement ; ce texte fait partie intégrante du document.
Une entité non-analysable est une ressource dont le contenu n'est pas nécessairement textuel. À chaque entité non-analysable est associée une notation, identifiée par un nom. XML n'impose aucune contrainte au contenu des entités non-analysables, mais exige seulement que les noms des entités et des notations soient mis à la disposition de l'application.
Les entités analysables sont appelées par leur nom au moyen d'un appel d'entité ;
le nom des entités non-analysables est donné par la valeur d'un attribut de
type ENTITY ou ENTITIES.
Les entités générales sont destinées à être utilisées dans le contenu du document. Les entités paramètres sont des entités analysables destinées à être utilisées dans la DTD. Les appels à ces deux types d'entités sont différents et sont reconnus dans des contextes différents. De plus, les deux types occupent des espaces de noms distincts ; une entité paramètre et une entité générale de même nom sont deux entités distinctes. Dans ce texte, les entités générales sont parfois appelées simplement entités quand il n'y a pas de risque d'ambiguïté.
On déclare les entités de la façon suivante:
entité générale
<!ENTITY Nom ValeurEntité > |
entité paramètre
<!ENTITY % Nom ValeurEntité > |
Les entités peuvent être soit internes soit externes.
Exemple de déclaration d'entité interne :
<!ENTITY Avancement "Ouf ! J'ai presque terminé
cette partie."> |
Exemples de déclaration d'entité externe :
<!ENTITY écoutille-ouverte
|
Une notation identifie par un nom le format d'une entité non-analysable, le format d'un élément muni d'un attribut notation ou l'application cible d'une instruction de traitement.
Une déclaration de notation donne un nom à la notation, nom servant dans les déclarations d'entité et de liste d'attributs et dans les stipulations d'attribut, ainsi qu'un identificateur externe qui peut permettre à un processeur XML ou à son application cliente de repérer un assistant capable de traiter des données en cette notation.
<!NOTATION NomNotation SYSTEM Valeur> |
Exemple:
<!NOTATION images SYSTEM "/usr/local/ressources/images">
|
Un appel de caractère fait référence à un caractère particulier du jeu de caractères ISO/CEI 10646, pour afficher par exemple un caractère inaccessible par le biais du clavier.
Si un appel de caractère commence par « &#x »,
les chiffres et lettres jusqu'au terminateur ";"
constituent une représentation hexadécimale de la position de code du caractère
dans l'ISO/CEI 10646.
S'il commence seulement par « &# »,
les chiffres jusqu'au terminateur ";" constituent
une représentation décimale de cette position de code.
Exemple:
é -> Appel du caractère é en
notation décimaleé -> Appel du caractère é en notation
hexadécimale |
Un appel d'entité fonctionne de la même façon qu'un appel de caractères, il
fait référence au contenu d'une entité nommée déclarée dans la DTD.
Les appels à des entités générales analysables utilisent l'esperluette
« & » et le point-virgule ";"
comme délimiteurs.
Les appels d'entités paramètres utilisent le symbole pour cent « % »
et le point-virgule ";" comme délimiteurs.
Comme un exemple vaut mieux qu'un long discours :
Appelons par exemple ce fichier accueil.xml
<?xml version="1.0"?> |
Et celui là bonjour.dtd
<!ELEMENT accueil (#PCDATA)> |
Voici le résultat :
| La Peste : Albert Camus, © 1947 Éditions Gallimard . Tous droits réservés |
Le format DSSSL est utilisé pour le rendu des documents SGML.
Il permet :
Si vous voulez tout savoir sur SGML/DSSSL, visitez http://heuss.techfak.uni-bielefeld.de/www/mreinsch/dsssl. Le site est en anglais mais vaut vraiment le détour.
Voici un petit exemple de SGML avec une feuille de style DSSSL :
Petit document avec sa DTD
<!DOCTYPE HTMLLite [ <!ELEMENT HTMLLite O O (H1|P)* > <!ELEMENT (H1|P) - - (#PCDATA|EM|STRONG)*> <!ELEMENT (EM|STRONG) - - (#PCDATA)> ]> <HTMLLite> <H1>Ceci est le titre</H1> <P>Ceci est du texte</P> <P>Ceci est en <em>italique</em></P> <P>Ceci est en <strong>gras</strong></P> </HTMLLite> |
Feuille de style associée
<!DOCTYPE style-sheet
system "style-sheet.dtd" >
(element HTMLLite
(make simple-page-sequence))
(element H1
(make paragraph
font-family-name:
"Times New Roman"
font-weight: 'bold
font-size: 20pt
line-spacing: 22pt
space-before: 15pt
space-after: 10pt
start-indent: 6pt
first-line-start-indent: -6pt
keep-with-next?: #t))
(element P (make paragraph
font-family-name:
"Times New Roman"
font-size: 12pt
line-spacing: 13.2pt
space-before: 6pt
start-indent: 6pt
quadding: 'start))
(element EM (make sequence
font-posture: 'italic))
(element STRONG (make sequence
font-weight: 'bold))
|
| Voici le spectaculaire
résultat
Ceci est le titre Ceci est du texte Ceci est en italique Ceci est en gras |
|
Veuillez noter au passage que la DTD est intégrée au document, en SGML elle est obligatoire.
Introduction
Les Cascading Style Sheets ou Feuilles de Styles en Cascade
ont été initialement conçues pour le langage HTML. La première version du standard,
dite CSS niveau 1 (CSS1), a été publiée en 1996.
En mai 1998, le W3 Consortium a publié une nouvelle version, dite CSS niveau
2 (CSS2). Celle-ci introduit des possibilités nouvelles par rapport à CSS-1,
notamment la notion de type de média qui donne la possibilité de spécifier
la mise en page d'un document en vue de son affichage sur écran, de son impression
sur papier, ou d'indiquer les conditions de sa réalisation par synthèse vocale
ou sur des terminaux braille.
CSS-1 et CSS-2 s'appliquent parfaitement bien à XML.
Ce nom barbare signifie simplement que les instructions de mise en page sont utilisées par ordre d'apparition, et que les surcharges sont possibles. Par exemple, si un style A définit une police Arial et une couleur bleue, on peut dans le document demander un style A avec une couleur rouge, qui remplacera temporairement le bleu dans une portion de document.
Les spécifications complètes se trouvent à l'adresse suivante http://www.w3c.org/TR/CSS
Implémentation
L'implémentation des feuilles de styles en cascade peut se faire de plusieurs manières :
- en incluant en-tête de page HTML les styles que l'on souhaite employer dans la page en question.
- en écrivant notre feuille de style dans un fichier séparé.
Cette seconde solution est celle qui a été retenue pour l'utilisation avec XML, et c'est la plus commode. Son principal avantage étant sa réutilisation pour d'autres document. Après tout pourquoi se fatiguer !
Cela s'écrit de la façon suivante :
<?xml version='1.0'?> |
Concepts de base
Il est facile de concevoir des feuilles de style simples. Cependant il est
nécessaire de connaître un minimum la programmation HTML/XML "à la main".
Par exemple pour définir la couleur bleue à l'élément (ou balise) H1,
on écrira :
H1 { color: blue } |
La règle de style
Une règle de style se compose d'un sélecteur qui indique l'élément auquel elle s'applique, et d'une ou de plusieurs propriétés ainsi que leur valeur respective. Le couple propriété: valeur forme ce que l'on appelle la déclaration.
sélecteur {propriété1: valeur ; propriété2: valeur } |
Notre exemple se décompose donc ainsi :

Le groupage
Afin de réduire la taille d'une feuille de style et d'en accroître la lisibilité, on peut regrouper les sélecteurs en les séparant par une virgule.
H1, H2, H3 { font-family: arial } |
De la même façon on peut regrouper les déclarations.
H1 { |
De plus, certaines propriétés peuvent avoir leur propre groupement de syntaxe. L'exemple ci-dessous est identique à celui présenté précédemment.
H1 { font: bold 12pt/14pt arial } |
Héritage
Dans le premier exemple, nous avons spécifié la couleur bleue à l'élément H1. Supposons maintenant que nous avons un élément en italique à l'intérieur de celle-ci.
<H1>Le titre d'un document <EM>est</EM> très important
!</H1> |
Si aucune couleur n'a été spécifiée pour l'élément EM, le mot en italique "est" héritera automatiquement de la couleur de son élément parent (H1), soit bleue pour notre exemple. Il en va également de même pour toutes les autres propriétés à savoir font-family, font-size, etc...
Pour définir un style "par défaut" pour tout un document il suffit de définir l'élément parent à tous les autres - c'est ce qu'on appelle aussi couramment élément racine - soit en HTML, l'élément <BODY>. En XML, je vous laisse imaginer le nom de cet élément.
exemple :
BODY { |
Sélecteur de classe
Afin d'accroître le contrôle de granularité sur les éléments, un nouvel attribut a été ajouté à HTML : 'CLASS'. Tous les éléments contenus dans l'élément racine peuvent être regroupés par classe. Ces classes seront définies dans la feuille de style.
<HTML> |
Dans cet exemple, nous avons "surchargé" l'élément H1 tel que défini dans la feuille de style qui est cette fois intégrée à notre document. Cependant nous aurions pu la concevoir à part.
Si nous avions voulu utiliser la classe 'citation' pour tous les éléments
Introduction
Dans ce chapitre je vais essayer de vous présenter brièvement les concepts de base des feuilles de style XSL en m'appuyant sur le document de travail du W3C de Juillet 1998 car, c'est sur celui-ci que s'appuie en partie Internet Explorer 5.0.
Les informations que vous trouverez dans cette partie différeront peut-être un peu de la norme étant donné que pour faire fonctionner nos exemples avec IE 5.0 il m'a fallu les adapter "à la sauce" Microsoft. A partir de là, il est possible qu'en fonction de l'évolution de la norme et des prochaines versions d'Internet Explorer que nos exemples ne fonctionnent plus. Cependant l'essentiel est de comprendre le principe de fonctionnement de cette nouvelle norme.
Ce que nous essayerons de comprendre :
XSL est particulièrement puissant dans le sens ou l'on peut à partir du document source obtenir un document résultat qui peut être très différent. Par exemple, on pourrait créer des graphiques à partir des valeurs contenues dans le document XML, de même que l'on pourrait bâtir automatiquement un sommaire et un index et tout ça sans modifier le document original.
Généralités
Ce qu'il faut retenir, c'est que pour définir une règle de style il faut :
| 1. décrire le squelette ou arbre du document
(cf. XSLT: XSL Tree)
|
 |
| 2. décrire le style que l'on veut appliquer à chaque articulation du squelette ou à chaque de noeud de l'arbre |  |
En effet comme nous l'avons vu précédemment un document XML est vu auprès d'un interprèteur XML (ou parser) comme une structure arborescente, un peu à l'image d'une arborescence d'un disque dur.
La règle du patron
A ne pas confondre avec votre "boss", la règle que j'appellerai du
"patron" ou template rule si vous préférez décrit la structure de
chaque noeud de l'arbre ainsi que le style à appliquer à ce noeud.
Une feuille de style XSL est tout simplement un document XML qui contient tout
un ensemble de règles. Ainsi, comme tout bon document XML elle doit suivre les
règles de construction afin d'être bien formée.
Cette règle se décompose en deux parties :
Un motif sélectionne un noeud (en fait une balise ou élément) en utilisant un ou plusieurs des critères suivants :
Le formatage de l'arbre
Dans l'ancienne spécification, la mise en forme des noeuds de l'arbre se fait
en utilisant les balises du jeu d'instruction de HTML; c'est actuellement ce
qui fonctionne avec Internet Explorer 5.0.
Dans la nouvelle spécification, la mise en forme ressemble plus à la syntaxe
de CSS à laquelle quelques éléments on été scindés pour d'augmenter la précision
du formatage des documents.
Voici à quoi ressemble XSL dans sa nouvelle mouture:
<xsl: template match="accueil"> |
Exemple
Afin d'être un peu plus concrets voyons un exemple très simple.
Voici le document XML :
<accueil>Bonjour monde !</accueil> |
Et voici notre fichier XSL (légèrement simplifié afin de comprendre sa structure) :
<xsl:stylesheet> |
Voilà le résultat :
Bonjour monde ! |
Dans cet exemple basique, nous avons sélectionné l'élément racine du document
(root) qui est en réalité notre document tout entier en utilisant élément template
avec l'attribut match.
Ensuite nous recherchons l'élément ou balise accueil en utilisant le
mot clé value-of select que nous encadrons par les balises
de mise en forme HTML.
Vous pouvez remarquer que tous les éléments XSL sont préfixés par xsl:, ceci est obligatoire et constitue ce que l'on appelle l'espace de nom ou name-space. Les espaces de nom sont utilisés afin de bien dissocier les différentes syntaxes que l'on peut trouver dans un document XML.
Conclusion
Je ne m'attarderais donc pas plus pour l'instant sur la norme XSL car les spécifications n'étant pas encore achevées tout ce que je pourrai vous décrire aujourd'hui ne sera plus valable demain. En effet, Microsoft Internet Explorer 5.0 étant le seul à implémenter une partie de cette norme s'appuie sur des spécifications ultérieures à celle que l'on connaît actuellement. De plus, XSL est une norme relativement complexe à mettre en oeuvre et assez controversées par les différents acteurs du marché.
Par conséquent, je pense qu'il est encore trop tôt pour utiliser XSL mais qu'il
vaut mieux à l'heure actuelle utiliser plutôt XML + CSS qui fonctionnent très
bien ensemble et qui sont à peu près conformes aux standards.
De cette manière, vos documents XML auront toutes les chances de perdurer.